Ontology in Earth Science
At the linked.earth meeting in Boulder, CO (June 22 - 23) we really started digging into ontologies. In building the DOI system and landing pages for Neotoma I’ve been thinking about ways to build out our system so that more information can be contained in the Landing Page documents, extending the ability of web technologies to harvest & gather information about the scientific content embedded in the records. This has led me to several key resources for building web-readable content to supplement landing pages.
FOAF (Friend Of A Friend)
foaf is a pretty standard ontology. It is named after the acronym “Friend of a Friend” and is used to describe people, their relationships and their activities. The foaf specification is very extensive, and, frankly, I’ve found the documentation somewhat opaque. That said, I’m still fairly new at working my way through these documents.
The key use for foaf is describing our author data in Neotoma. Using either JSON or RDF/XML it’s possible to directly translate most author and institutional data to some form of RDF. I wrote out a code snippet that I use as header in my webpage (it’s written as a <script> element, so you can’t see it) that describes who I am, what projects I belong to (Neotoma & EarthCube). The schema below uses RDF/XML, but my feeling is that I’ll probably rewrite this as JSON-LD, especially since the standards are so nicely written! (FYI - There’s a great blog post about the standards here).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:admin="http://webns.net/mvcb/">
<foaf:Person rdf:ID="me">
<foaf:name xml:lang="en">Simon J. Goring</foaf:name>
<foaf:givenname>Simon</foaf:givenname>
<foaf:family_name>Goring</foaf:family_name>
<foaf:homepage rdf:resource="http://goring.org"/>
<foaf:publications rdf:resource="http://simongoring.github.io/cv/Publications.html"/>
<foaf:schoolHomepage rdf:resource="http://www.wisc.edu"/>
<!-- This next line is an obscured email address! -->
<foaf:mbox_sha1sum>4f9fb359d3396b0eda825202f843508eaeb26f79</foaf:mbox_sha1sum>
<!-- Here's my ORCID account -->
<foaf:account>
<foaf:OnlineAccount>
<foaf:accountServiceHomepage rdf:resource="http://www.orcid.org"/>
<foaf:accountName>0000-0002-2700-4605</foaf:accountName>
<foaf:accountProfilePage rdf:resource="http://www.orcid.org/0000-0002-2700-4605#person"/>
</foaf:OnlineAccount>
</foaf:account>
<!-- And my Twitter account (follow me!) -->
<foaf:account>
<foaf:OnlineAccount>
<foaf:accountServiceHomepage rdf:resource="http://www.twitter.com/"/>
<foaf:accountName>sjGoring</foaf:accountName>
<foaf:accountProfilePage rdf:resource="http://www.twitter.com/sjGoring"/>
</foaf:OnlineAccount>
</foaf:account>
<!-- Some of the things I'm working on! -->
<foaf:currentProject>
<foaf:Project>
<foaf:organization>Neotoma Paleoecological Database</foaf:organization>
<foaf:homepage rdf:resource="http://neotomadb.org"/>
</foaf:Project>
</foaf:currentProject>
<foaf:currentProject>
<foaf:Project>
<foaf:organization>EarthLife Consortium</foaf:organization>
<foaf:homepage rdf:resource="http://earthlifeconsortium.org" />
</foaf:Project>
</foaf:currentProject>
<!-- And that's it, let's close this out. -->
</foaf:Person>
</rdf:RDF>
PROV
Prov is an ontology used to describe the provenance of objects and activities. It can focus on the agent of change in the system, the object that is changed across the chain of provenance, or the activities, carried out by the agents on a set of objects. The PROV data model is of particular interest. Part of our motivation for beginning to mint DOIs for Neotoma – described more fully here – was so that we could provide them as currency for the exchange of data between related databases, or between workflow tools.
PROV would allow us to link raw pollen count data to resources like OpenCoreData or LacCore, where the lake sediment for the lacustrine cores might be stored. We could establish a Chain of Provenance for materials and measurements from the field to publication.
owl-time
The time ontology in OWL is more complex and we’re working through it slowly. The complexity comes from the inherent uncertainty in relating stratigraphic position of a sample within a sediment core to a calibrated temporal measurement. In particular, pollen samples are obtained from sediment within a core, a physical interval with (initially) unknown temporal bounds. Even when we build a chronology, most pollen samples are not directly dated, and dates for individual depth intervals are known with non-normal uncertainty bounds.
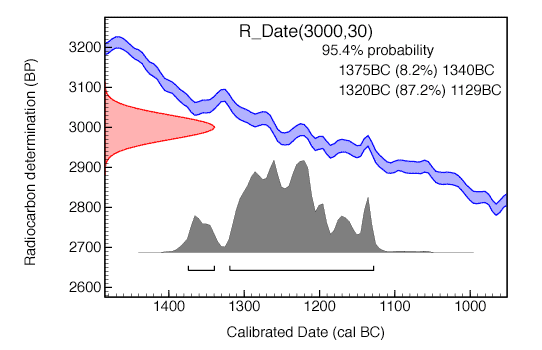
As far as we can see, it is a challenge to have adjacent physical samples with overlapping age bounds, but a constraint that ages are monotonically increasing with depth (in theory). A full implementation would have to pair descriptions of things, time, provenance, some description of the methods for chronology generation. In essence, all of the work we’ve done with Neotoma to fully (and successfully) model paleoecological data needs to be translated into a web-accessible ontology.
This is not simple work, and needs some time to sort out.
The current design for Neotoma’s Landing pages (current as of October 14, 2016) uses the schema.org schemas, implemented in JSON-LD (as mentioned above). The implementation looks something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
{
"@context": "http://schema.org",
"@type": "Dataset",
"license": "https://creativecommons.org/licenses/by/4.0/deed.en_US",
"author": {
"@type":"Person",
},
"includedInDataCatalog": {
"@type": "DataCatalogue",
"about": "Paleoecology",
"publisher": {
"@type": "Organization",
"name": "Neotoma Paleoecological Database",
"alternateName":"Neotoma",
"description":"The Neotoma Paleoecology Database and Community is an online hub for data, research, education, and discussion about paleoenvironments.",
"url": "http://neotomadb.org"
},
"funder": {
"@type":"Organization",
"name":"National Sciences Foundation",
"alternateName": "NSF",
"url": "http://nsf.gov"
}
},
"about": "Pollen dataset",
"distribution":{
"@type":"DataDownload",
"contentUrl":"http://api.neotomadb.org/v1/data/downloads/1001",
"datePublished": "2016-08-12",
"inLanguage": "en"
},
"spatial": {
"@type": "Place",
"name": "Hail Lake",
"geo": {
"@type": "GeoCoordinates",
"latitude": "0.01",
"longitude": "0.01",
"elevation": "0"
}
}
}
}
This code block would be dynamically generated at the time of creation, using metadata stored in the Neotoma Database. It’s described more fully in the DOI Assignment project repository.